Ostatnia aktualizacja: 9 lutego 2025
Żyjemy w czasach, w których ilość informacji rośnie w zawrotnym tempie. Czasem znalezienie odpowiedzi na konkretne pytanie przypomina szukanie igły w stogu siana. Czy jest na to sposób? Owszem! Pokażę Ci, jak stworzyć własną wyszukiwarkę semantyczną, która nie tylko znajdzie dane, ale zrozumie ich kontekst. Do tego wykorzystamy biblioteki LangChain i Chroma w języku Ruby.
System RAG (Retrieval-Augmented Generation) – jak działa?
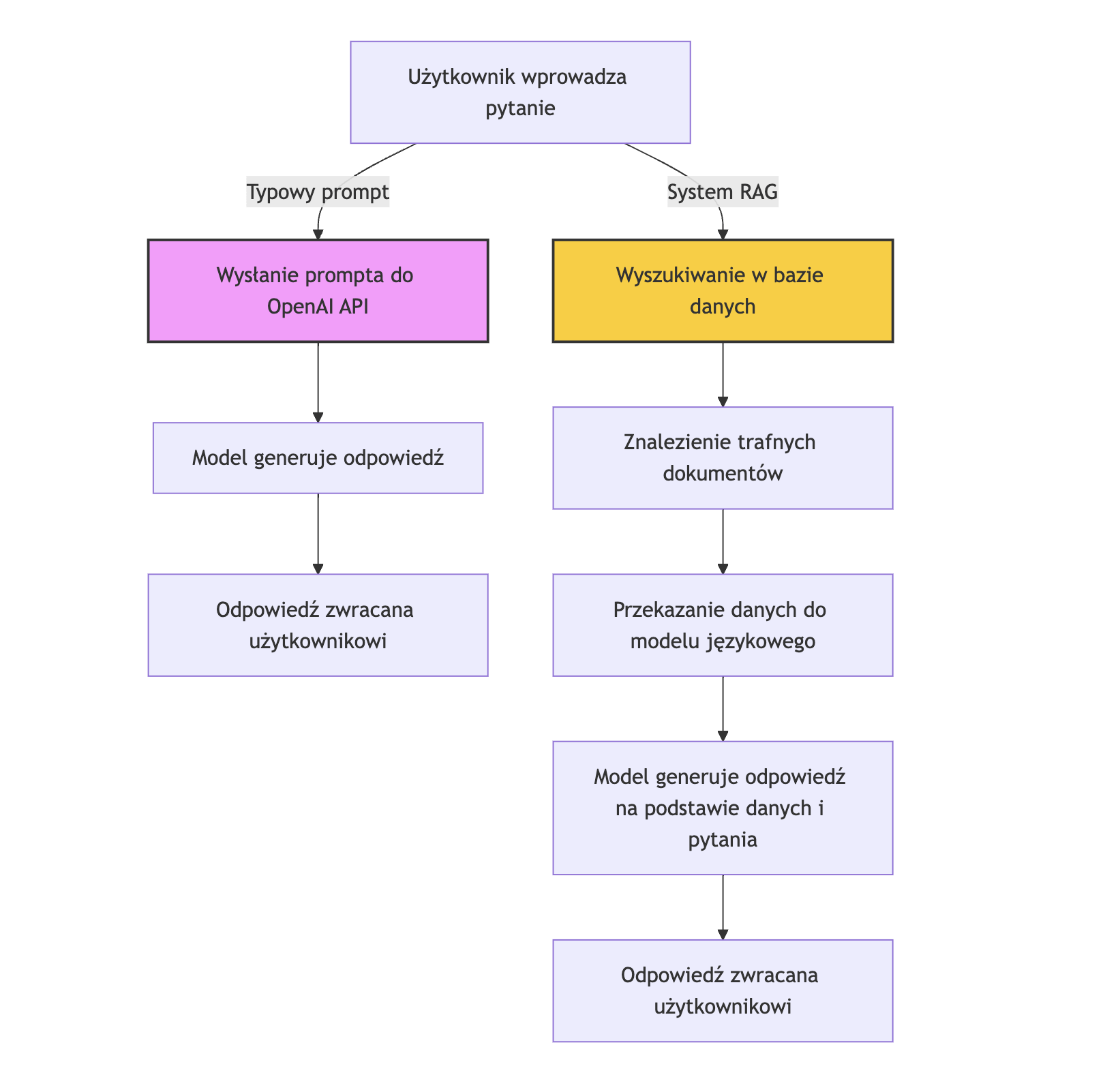
System RAG pozwala łączyć zalety baz danych i modeli językowych. Dzięki temu możliwe jest tworzenie bardziej precyzyjnych i kontekstowych odpowiedzi na pytania użytkownika.
Wyszukiwanie informacji (Retrieval) – gdy użytkownik zadaje pytanie, system najpierw przeszukuje bazę danych (np. w oparciu o wektory) w celu znalezienia najbardziej trafnych informacji. Wykorzystywane są tutaj technologie takie jak bazy wektorowe (np. Chroma), które umożliwiają semantyczne dopasowanie danych.
Generowanie odpowiedzi (Generation) – po znalezieniu odpowiednich informacji, system przekazuje je do modelu językowego (np. GPT-4). Model ten generuje odpowiedź, bazując zarówno na wynikach wyszukiwania, jak i swojej wiedzy.
Przygotowałam schemat, który porównuje wysyłanie standardowego zapytania do OpenAI z przesłaniem prompta do systemu RAG:
Jakich bibliotek użyjemy do implementacji?
Wyszukiwarka semantyczna to narzędzie, które rozumie znaczenie tekstu, a nie tylko wyszukuje pasujące słowa kluczowe. Tutaj wchodzą LangChain i Chroma – dwie biblioteki, które usprawniają pracę z modelami językowymi i danymi wektorowymi.
- LangChain: To narzędzie stworzone z myślą o pracy z modelami językowymi, takimi jak GPT-4. Ułatwia tworzenie promptów, zarządzanie kontekstem i integrację z różnymi modelami AI. Krótko mówiąc – to most między Twoim kodem a zaawansowanymi modelami językowymi.
- Chroma: To baza danych zaprojektowana do pracy z wektorami. Pozwala przechowywać dane w formie, która umożliwia zaawansowane wyszukiwanie semantyczne. Dzięki temu Twoja wyszukiwarka znajdzie nie tylko dane, ale i ich kontekst.
No to przystąpmy do dzieła 🙂
Przygotowanie środowiska
Zanim zaczniemy budować wyszukiwarkę semantyczną, musimy przygotować odpowiednie środowisko pracy. Oto potrzebne kroki:
1. Zainstaluj Ruby i niezbędne biblioteki
Upewnij się, że masz zainstalowany Ruby oraz potrzebne do projektu biblioteki. W swoim pliku Ruby dodaj następujące zależności:
require 'langchain'
require 'nokogiri'
require 'chroma-db'Dodatkowo, uruchomimy kontener Dockera z Chromą:
docker run -p 8000:8000 chromadb/chroma
Informacje jak pobrać i zainstalować Chromę znajdziesz pod tym linkiem: https://docs.trychroma.com/deployment/docker
2. Integracja z Modelem Językowym
Aby korzystać z modelu językowego, potrzebujemy klucza API oraz identyfikatora modelu. Ważne jest, aby klucza API nie umieszczać bezpośrednio w kodzie źródłowym jeśli planujemy dzielić się nim z innymi. Można zamiast tego użyć zmiennych środowiskowych jak na przykładzie poniżej:
API_KEY = ENV['OPENAI_API_KEY']
MODEL_ID = 'gpt-4o-mini'Dalej inicjalizujemy model OpenAI za pomocą biblioteki LangChain, przekazując klucz API oraz nazwę modelu:
model = Langchain::LLM::OpenAI.new(
api_key: API_KEY,
default_options: { model_name: MODEL_ID }
)3. Pobieranie danych i zasilanie nimi bazy wektorowej
Nasza baza lokalna, której dane będziemy wykorzystywać do wzbogacania zapytań, jest na razie pusta. Dla przykładu zapełnimy ją informacjami z mojej strony głownej. Wykorzystamy do tego bibliotekę Langchain::Loader:
loader = Langchain::Loader.load('https://justynawojtczak.com')
Tak pobrany sutrowy tekst może być zbyt obszerny i wymaga dalszej obróbki – zastosujemy tzw. chunking, czyli podział tekstu na mniejsze fragmenty.
4. Chunking – dzielenie tekstu na fragmenty
Chunking pomaga w efektywnym przetwarzaniu dużych ilości tekstu przez modele językowe. Ustawiamy rozmiar fragmentu oraz nakładanie się fragmentów, aby zachować ciągłość kontekstu.
chunker = Langchain::Chunker::RecursiveText.new(
loader.value,
chunk_size: 200,
chunk_overlap: 20,
separators: [".\n\n", "\n\n", ".\n", "\n", ". "]
)Tutaj dzielimy tekst na fragmenty o długości 200 znaków, z 20-znakowym nakładaniem. Separatory pomagają w 'inteligentnym’ podziale tekstu, zachowując zdania i akapity w całości.
5. Połączenie do bazy wektorowej Chroma i zasilenie danymi
Teraz, gdy mamy przygotowane paczki tekstu, możemy je zaindeksować w Chromie. Inicjalizujemy klienta Chroma, wskazując na uruchomiony wcześniej serwer oraz przekazując model językowy. Aby nasza wyszukiwarka mogła działać, musimy dodać przetworzone fragmenty tekstu do indeksu.
client = Langchain::Vectorsearch::Chroma.new(
url: 'http://localhost:8000',
index_name: 'blog',
llm: model
)
client.add_texts(texts: chunker.chunks.map(&:text))
6. Tworzenie promptu, który zwróci właściwy format odpowiedzi
Biblioteka Langchanin umozliwia tworzenie promptu z przygotowanego template. Można w nim zdefiniować zmienne, które przekazujemy podczas inicjalizacji tego template. W naszym przypadku taką zmienną jest 'question’ czyli pytanie zadawane przez użytkownika.
Aby uzyskać właściwy format odpowiedzi, użyłam sposobuzwanego few-shot in-context. W prompcie dostarczam przykłady pytania i odpowiedzi z nadzieją, że API OpenAI zwróci mi w taki sam sposób wynik.
question = 'Co Justyna tworzy z koralików?'
template = """Odpowiedz na pytanie, używając najpierw kontekstu, a następnie poszukaj własnej odpowiedzi. Dodaj odpowiednią adnotację do swojej odpowiedzi, jak w przykładach.
Przykłady:
Kontekst: Niebo jest niebieskie.
Pytanie: Jakiego koloru jest niebo?
Odpowiedź: Niebieskie.
Adnotacja: Odpowiedź jest w kontekście.
Kontekst: Kwiat jest czerwony.
Pytanie: Jakiego koloru jest niebo?
Odpowiedź: Niebieskie.
Adnotacja: Odpowiedź nie jest w kontekście.
Pytanie: {question}
"""
prompt = Langchain::Prompt::PromptTemplate.new(template: template, input_variables: ['question'])
formatted_prompt = prompt.format(question: question)
7. Wykonanie zapytania do wyszukiwarki
Korzystam z klienta Chroma, które zainicjalizowałam w punkcie nr 5.
client.ask(question: formatted_prompt, k: 2)Działanie jest dość złożone, i polega na odpytaniu API OpenAI, zwróceniu wyniku w formacie wektorowym, nastepnie odpytania bazy wektorowej i wysłaniu tego wyniku ponownie do API OpenAI i zwrócenie wyniku:
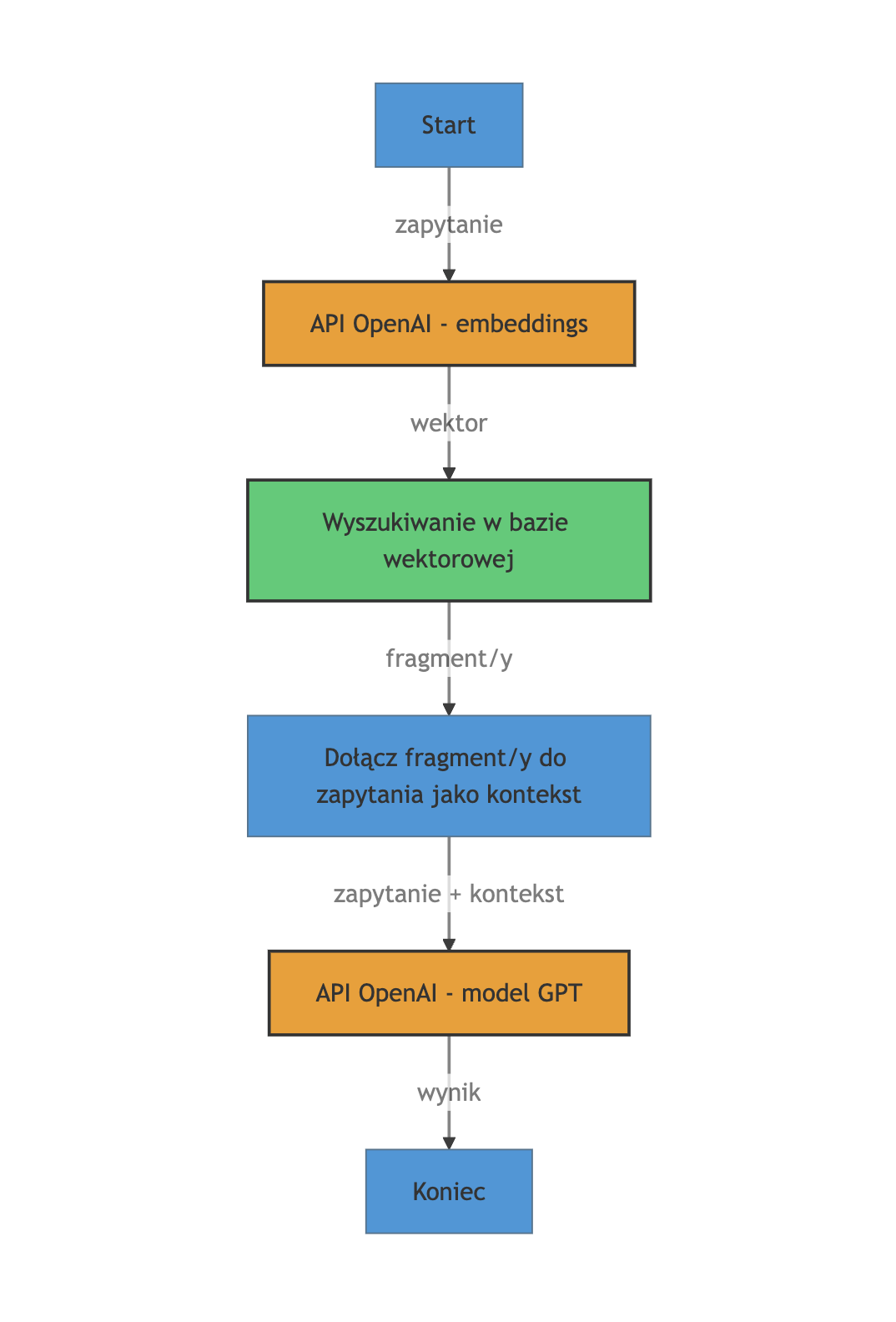
Połączenie wszystkich kroków
Pozwoliłam sobie trochę zrefaktoryzować kod i po połączeniu wszystkich punktów wygląda on tak:
require 'langchain'
require 'nokogiri'
require "chroma-db"
# docker run -p 8000:8000 chromadb/chroma
API_KEY = nil # tu wstaw swój klucz do API OpenAI
MODEL_ID = 'gpt-4o-mini'
CHROMA_URL = 'http://localhost:8000'
INDEX_NAME = 'blog'
SOURCE_URL = 'https://justynawojtczak.com'
# Inicjalizacja modelu
def initialize_model(api_key, model_id)
Langchain::LLM::OpenAI.new(
api_key: api_key,
default_options: { model_name: model_id }
)
end
# Pobieranie i przetwarzanie treści
def load_and_chunk_content(source_url)
loader = Langchain::Loader.load(source_url)
chunker = Langchain::Chunker::RecursiveText.new(
loader.value,
chunk_size: 200,
chunk_overlap: 20,
separators: [".\n\n", "\n\n", ".\n", "\n", ". "]
)
chunker.chunks.map(&:text)
end
# Inicjalizacja klienta Chroma
def initialize_chroma_client(url, index_name, model)
Langchain::Vectorsearch::Chroma.new(
url: url,
index_name: index_name,
llm: model
)
end
# Sprawdzenie i tworzenie indeksu, jeśli nie istnieje
def ensure_index_exists(client)
client.create_default_schema
true
rescue Chroma::APIError
false
end
# Dodawanie tekstów do indeksu
def add_texts_to_index(client, texts)
client.add_texts(texts: texts)
end
# Tworzenie sformatowanego promptu
def create_prompt(question)
template = <<~TEMPLATE
Odpowiedz na pytanie, używając najpierw kontekstu, a następnie poszukaj własnej odpowiedzi. Dodaj odpowiednią adnotację do swojej odpowiedzi, jak w przykładach.
Przykłady:
Kontekst: Niebo jest niebieskie.
Pytanie: Jakiego koloru jest niebo?
Odpowiedź: Niebieskie.
Adnotacja: Odpowiedź jest w kontekście.
Kontekst: Kwiat jest czerwony.
Pytanie: Jakiego koloru jest niebo?
Odpowiedź: Niebieskie.
Adnotacja: Odpowiedź nie jest w kontekście.
Pytanie: #{question}
TEMPLATE
template
end
# Główna funkcja zadająca pytanie
def ask_question(question)
# Sprawdzenie obecności klucza API
unless API_KEY
puts "Brak klucza API. Ustaw zmienną środowiskową 'OPENAI_API_KEY'."
return
end
# Inicjalizacja modelu
model = initialize_model(API_KEY, MODEL_ID)
# Inicjalizacja klienta Chroma
client = initialize_chroma_client(CHROMA_URL, INDEX_NAME, model)
# Sprawdzenie i tworzenie indeksu, jeśli nie istnieje
index_created = ensure_index_exists(client)
# Jeśli indeks został stworzony, dodajemy teksty do indeksu
if index_created
# Pobieranie i przetwarzanie treści
texts = load_and_chunk_content(SOURCE_URL)
# Dodawanie tekstów do indeksu
add_texts_to_index(client, texts)
else
puts "Indeks '#{INDEX_NAME}' już istnieje. Pomijam dodawanie tekstów."
end
# Tworzenie promptu
formatted_prompt = create_prompt(question)
# Zadawanie pytania
response = client.ask(question: formatted_prompt, k: 2)
puts response
end
# Przykładowe wywołanie funkcji
ask_question('Co Justyna tworzy z koralików?')
I odpowiedź:
{
"id": "chatcmpl-Ab3qLLhXwSg2eNPIILADbg7p5mHbt",
"object": "chat.completion",
"created": 1733396273,
"model": "gpt-4o-mini-2024-07-18",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Odpowiedź: Justyna tworzy biżuterię, w tym bransoletki i wisiorki z koralików. \nAdnotacja: Odpowiedź jest w kontekście.",
"refusal": null
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 260,
"completion_tokens": 46,
"total_tokens": 306,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"system_fingerprint": "fp_0705bf87c0"
}Podsumowanie
Mam nadzieję, że nie wyszło zbyt skomplikowanie i że ten przewodnik wyjaśnił kluczowe kroki niezbędne do stworzenia własnego rozwiązania. Zachęcam Cię do eksperymentowania, modyfikowania kodu i dostosowywania go do swoich potrzeb. W ten sposób możesz stworzyć system, który nie tylko ułatwia pracę, ale także rozwiązuje rzeczywiste problemy. 🚀

Programistka, artystka koralikowa i wieloletnia praktyczka diety LCHF. Autorka ketolabs.pl. Koraliki od 2017 — peyote, CRAW, herringbone, krosno i więcej.
Skomentuj pierwszy